C’est une tres bonne question et je te remercie de l’avoir posée ^^
A aucun moment l’api n’accède aux données de la base, le seul entrainement fournit concerne la structure des données. c’est d’ailleurs toute l’élégance de la solution.
Je suis cependant en train de réfléchir à une évolution qui transmettrait des données mais ce serait de manière anonyme (ex : prod1, prod2, en se basant sur l’id du produit ou client1, client2 pour les société)
mais je préfère rester dans le vague pour le moment (bon je peux en discuter en mp avec un NDA ^^).
Ho … avec quelques (tout petits) efforts … ça sera tellement pratique que le glissement ne se verra quasiment pas.
Quand on voit comment MS souhaite éventuellement intégrer ça dans la suite office ça me fait rêver … ce n’est qu’une question de temps.
Une piste ?
Étape 1 (l’outil n’a pas accès aux données) : je dicte une lettre « dis-moi ma belle ia peux tu rédiger une relance pour impayé à tous mes clients qui ont plus de 3 mois de retard » → ça fera une lettre générique
Étape 2: l’outil proposera d’une manière un peu sympa d’aller extraire le montant de la relance pour pouvoir l’intégrer dans le mail … « ça serait bien de pouvoir dire à vos clients combien ils vous doivent, voulez-vous que j’aille chercher l’information dans votre dolibarr, je sais que c’est la table llx_xxx ? »
vous voyez le glissement ?
Donc entre le contenu d’un courrier générique créé par un outil et le fait de lui « donner accès aux données » la frontière est mince non ?
Et puis d’une manière plus générale, on commence par proposer un truc gratuit, puis on restreint un peu l’accès en demandant un numéro de téléphone, une adresse mail, un compte outlook ce genre de choses et pas à pas une fois la dette technologique bien assurée hop on resserre un peu le collier…
Dans tous les cas il faudra bien chercher comment rentabiliser toutes ces dépenses qui se comptent en milliards car il ne faut pas se berner un jour où l’autre il sera question de revenir sur investissement et si c’est « gratuit en apparence » c’est qu’on cherche du mauvais côté qui est le produit…
Dans le cas de mon développement (je ne travaille pas encore chez M$…), le code est libre d’accès pour vérifier justement ce qui est envoyé ou non à l’API.
De ce que j’ai pu voir sur l’usage de l’API, la définition des couts est claire et précis selon le type de « moteur » que l’on emploie.
OpenAI a déjà en train d’annoncer des tarifs pour l’utilisation de leur outil et meme si je trouve le tarif non négligeable (42$/mois), je fais la part des choses sur le retour sur investissement en terme de temps économisé, que ce soit pour écrire du code ou pour ma part en ce moment d’automatiser des process d’intégration continue.
Prenons un exemple, actuellement, je ne met pas en place systématiquement des tests unitaires sur mes modules car je considère cela trop chronophage par rapport au gains estimé en terme de qualité mais si je peux générer rapidement ce code de test, il est probable que je mettrais en place plus de tests (au lieu de trouver un.e stagiaire pour lui faire réaliser cette tache…)
Oui je gagne du temps pour l’écriture de code « boring » ou de truc pointu mais pour le reste … on est loin du compte.
Il s’agit bien pourtant d’une révolution intellectuelle (parallèle avec la révolution industrielle) où les taches répétitives et fatigante sont réalisées par une machine (et je fais bien la différence philosophique entre un outil et une machine pour son autonomie à réaliser des taches simples).
Ce sont clairement les développeurs à bas coups qui seront remplacés, mais je doute vraiment d’être mise à la retraite prématurément
heu, j’ai l’impression qu’on mélange plein de choses, ma réponse était uniquement liée à « comment d’ailleurs penser qu’il puisse en être autrement… » dans le contexte « A aucun moment l’api n’accède aux données de la base, le seul entrainement fournit concerne la structure des données. »
Je me suis permis d’illustrer mon point de vue sur ce sujet et uniquement ce sujet.
Oui j’ai fait un pavé sur mes réflexions sur cette technologie, je réfléchis pas mal à l’impact que cette révolution va avoir et j’ai bien du mal …
J’ai suivis il y a plus d’un an une formation de data-analyst et tous ce qui avait trait au machine learning et à l’apprentissage en particulier me semblait alors complexe à mettre en oeuvre. Le retour sur investissement pour une société me semblait alors hasardeux.
Dans le cadre d’open AI, on est dans une autre logique, bien moins rigide et plus simple à employer qui permet justement un retour sur investissement rapide des utilisateurs, ce qui permet d’en justifier à mes yeux de le rendre payant.
Pour ma part je reçois régulièrement des demandes de création de requêtes SQL pour myList, mon module me permet de gagner pas mal de temps de développement mais il y a toujours un travail de finition, j’estime qd meme avoir réduit de 30% le temps pour réaliser cette tache
Rien que de voir comment certains utilise cette technologie pour le SEO, la rédaction d’article, ce sont des pans entiers d’activité dans les entreprises qui vont évoluer
Hello ce module semble tres interessant, j’ai un cas d’usage pour les requêtes complexes, par exemple
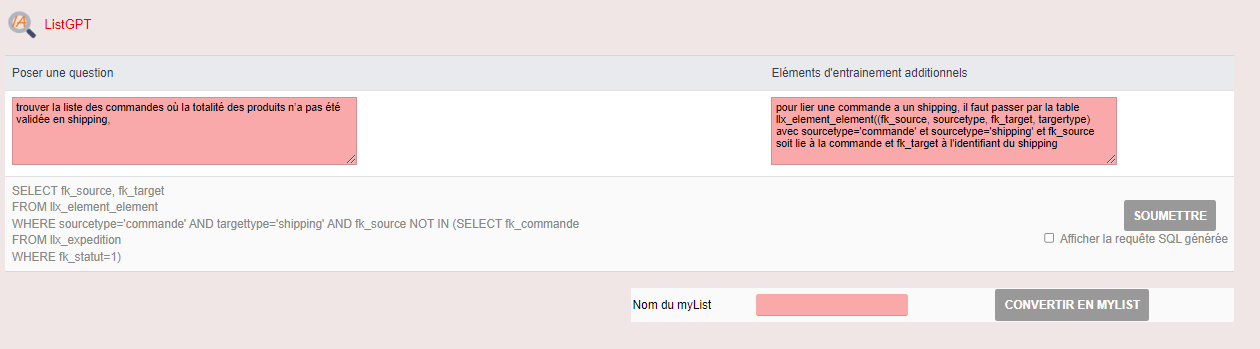
trouver la liste des commandes où la totalité des produits n’a pas été validée en shipping,
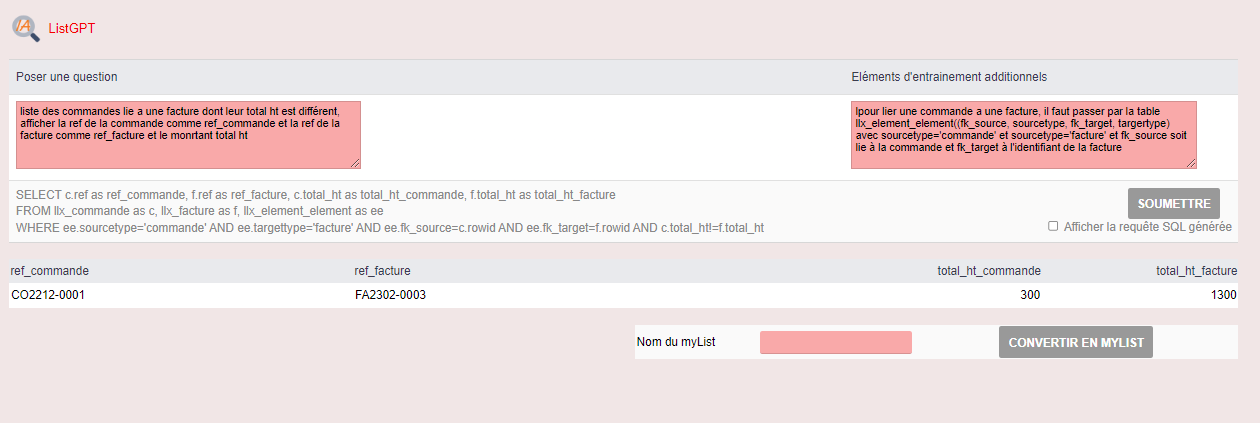
liste des commandes où le montant est different des factures: est-ce que tu pourrais m’expliquer comment faire la requête dans le fichier demo? Si ca marche j’achète direct haha.
Pour le moment l’entrainement de base contient pas la notion d’élément lié en natif, j’ai donc du ajouter cette information manuellement à l’entrainement
Il me manque au niveau de l’entrainement la notion de validation mais je constate qu’il a réussi à faire le lien avec la table ll_expedition tout seul (sans faire l’erreur d’un llx_shipping)
Pour la seconde c’est mieux encore
Je suis en train de travailler sur comment ajouter des entrainements additionnels en fonction des éléments présent dans la question, pour le moment je parts sur des cases à cocher mais j’aimerai beaucoup lui proposer de sélectionner lui-même ces infos dans une première étape
Dans la série des évolutions à venir, ajouter une habilitation pour bloquer les requetes contenant la table llx_user
Bonjour, je ne comprends pas grand chose a la reponse donnee, mais en gros puisque tu acceptes le challenge je peux telecharger l’application pour voir si ca marche avec mes donnees c’est ca :)?
Je peux taper la requete directement et il me listera ce qu’il trouve? Si ca marche ce sera super!
alors normalement oui, tu devrais pouvoir utiliser le module pour ton analyse,
mais dans ton cas, il faut aussi saisir des informations d’entrainement en plus ( le bloc à droite de l’écran)
Juste que pour la première question, cela demande plus d’information que je n’ai pas à savoir la notion de validation des produits
code-davinci
je n’ai pas trop remarqué de différence notable et comme le cout de l’appel à l’api ne changeait pas trop, j’ai préféré prendre celui qui avait les meilleurs performances sur le papier
Hello, j’ai acheté le module comme promis pour t’encourager!
En gros,
il y a des questions auxquelles le module ne répond pas: « clients qui ont des ventes en 2022 mais pas en 2021 », « compare les ventes entre 2022 et 2021 », et toutes les questions complexes en general.
des questions ou le module se trompe dans la formule: « meilleures ventes 2022 » donne un chiffre filtre sur 2021, et additionne les totaux des commandes au lieu de prendre le chiffre ligne par ligne. « Combien de produits XXX vendus en 2022 » renvoie soit un nombre de factures ou le produit apparait, soit pas de résultat, soit un chiffre d’affaire au lieu du nombre.
des questions qui marchent bien: nouveaux clients cette année / en 2021, c’est-a-dire toutes les requêtes faciles qui j’imagine correspondent a des tables sans liens compliques.
Bref c’est interessant mais en l’état a peu près inutilisable…
Est-ce que tu pourrais preciser comment on doit rentrer les infos dans la colonne « more training info »?
hello et merci pour ton achat quelques remarques :
premières chose toute bêtes, lui expliquer ce que tu entends par vente à savoir facture
pour ce qui est du détail des produits vendues, il faut effectivement lui préciser le liens avec la ligne de détail des ventes
D’expérience, et les témoignages ici le prouve, l’api d’open ai est qd meme capable de réaliser des requêtes complexes mais il est nécessaire de bien l’entrainer (et cet entrainement peu etre parfois long à réaliser (cf mes derniers exemples)
je vais répondre en particulier à ses deux questions :
Le but de ce développement était à la fois :
d’expérimenter l’usage d’une AI dans le domaine des ERP, comment interagir avec elle en terme d’entrainement.
de permettre à des personnes sans réelle connaissances en SQL de réaliser des requêtes plus ou moins complexes sur leur données.
Dans la colonne " more training info " permet de transmettre des informations supplémentaire à open AI, comme d’autre structures de tables ou des règles fonctionnelles propre à dolibarr (par exemple que les factures impayées on un fk_statut = 1
il faut donc pour remplir cette zone avoir des connaissances dans la structure des tables de Dolibarr. C’est sur ce point que je suis en train de travailler, à savoir apporter un ensemble de données d’entrainement en plus selon la thématique de la question (par exemple les structures de tables associé au ticket quand on pose une question sur ce sujet)
excuse-moi si ma réponse est maladroite, pour moi ChatGPT est quelque chose de complètement nouveau, je ne dis pas du tout que ton module est inutile, c’est juste que je ne sais pas comment l’utiliser et suis content d’experimenter avec pour voir si ca peut marcher Je trouve ca passionnant!
Concernant tes deux points, tout a fait d’accord sur le premier et l’experimentation, je comprends l’enjeu du deuxième point de ta réponse aussi, aujourd’hui le chat peut aider a formuler les requetes si on connait un peu les tables, et l’étape suivante serait de pouvoir formuler naturellement toutes les questions, mais ce n’est pas facile du tout.
J’ai plusieurs questions:
est-ce qu’on peut écrire indifféremment en anglais/francais/chinois les requetes?
Pour entrainer le modele, y a-t-il une manière correcte d’indiquer les tables a l’IA?
Comment la « formation » de l’AI fonctionne-t-elle? Si beaucoup de gens utilisent ton module, deviendra-t-il plus intelligent?
Même si j’ai des connaissances en Machine Learning de part une formation de Data-Analyst récente, je ne te cache pas que je découvre moi aussi et ChatGPT (comme beaucoup de monde il me semble) et ce dernier a pris beaucoup de place dans mon activité depuis sa sortie, il n’y a pas un jour ou je ne l’utilise pas.
Développer un module pour Dolibarr utilisant cette technologie était pour moi un vrai challenge et comme je travaille par évolution/amélioration successives de mes modules, il s’en vas de soit que celui-ci va évoluer au fur et à mesure de mes découvertes, tests, demande de mes clients…
A ma connaissance oui, mais je n’ai pas expérimenté en chinois ^^
Pour le moment je donne le nom de la table et les champs qui me semble « utile », je n’ai pas l’impression qu’en donnant pour entrainement 'en se basant sur l’architecture des tables SQL de Dolibarr" ou un lien vers vers le github de celles ci cela fonctionne
A ma connaissance c’est comme l’énoncé d’un exercice de math, on donne des informations que l’on pense utile pour qu’un élève réussisse son devoir (un peu comme pour le fusil de Tchekhov Fusil de Tchekhov — Wikipédia), plus l’élève est compétent, moins il a besoin d’informations…
A ma connaissance non, l’ia a une une compétence pour écrire des requetes SQL mais elle ne connait pas la structure des tables de dolibarr
Le problème de la « formulation naturelle » des questions c’est que le plus souvent elles ne veulent rien dire.
Je m’explique : dans mon boulot on me demande fréquemment de faire des exports à partir d’une ou plusieurs bases de données (pas Dolibarr, mais cela n’a pas d’importance pour l’explication).
Quand je reçois une demande d’export formulée ainsi "il me faut un export de tous les produits machinchose vendus en 2022", je suis incapable de répondre. Je ne peux pas deviner ce à quoi pense la personne qui formule cette demande.
Le terme « produits vendus » ne signifie rien pour moi. Je sais extraire des produits commandés, des produits facturés, des produits expédiés et des produits en retour SAV.
Ensuite je ne sais pas ce qu’il faut extraire comme information ni sous quelle forme. Faut-il un détail jour par jour, mois par mois ? Est-ce qu’on veut la quantité de produits ou le CA réalisé ou la marge, ou bien le tout ? De quelle date parle-t-on ? Date de commande, date d’expédition, date de facturation ?
Il en va de même pour l’IA, une demande floue et imprécise implique forcément un résultat qui aura peut de chances d’être correct.